Ang karaniwang paglihis ay isang karaniwang halaga. Mga parameter ng istatistika
Sa istatistikal na pagsubok ng mga hypotheses, kapag sinusukat ang isang linear na relasyon sa pagitan ng mga random na variable.
Karaniwang lihis:
Karaniwang lihis (pagtantiya ng karaniwang paglihis random variable Ang sahig, ang mga dingding sa paligid natin at ang kisame, x patungkol sa kanya inaasahan sa matematika batay sa isang walang pinapanigan na pagtatantya ng pagkakaiba nito):
nasaan ang pagpapakalat; - Ang sahig, ang mga dingding sa paligid natin at ang kisame, i ika elemento ng pagpili; - laki ng sample; - arithmetic mean ng sample:
Dapat tandaan na ang parehong mga pagtatantya ay may kinikilingan. Sa pangkalahatang kaso, imposibleng bumuo ng walang pinapanigan na pagtatantya. Gayunpaman, ang pagtatantya batay sa walang pinapanigan na pagtatantya ng pagkakaiba ay pare-pareho.
Tatlong sigma na panuntunan
Tatlong sigma na panuntunan() - halos lahat ng mga halaga ng isang normal na ibinahagi na random na variable ay nasa pagitan. Mas mahigpit - na may hindi bababa sa 99.7% kumpiyansa, ang halaga ng isang normal na ibinabahagi na random na variable ay nasa tinukoy na agwat (sa kondisyon na ang halaga ay totoo at hindi nakuha bilang resulta ng pagpoproseso ng sample).
Kung ang tunay na halaga ay hindi alam, kung gayon hindi natin dapat gamitin, kundi ang Sahig, ang mga dingding sa paligid natin at ang kisame, s. kaya, tuntunin ng tatlo ang sigma ay binago sa panuntunan ng tatlo Ang sahig, ang mga dingding sa paligid natin at ang kisame, s .
Interpretasyon ng standard deviation value
Ang isang malaking halaga ng karaniwang paglihis ay nagpapakita ng isang malaking pagkalat ng mga halaga sa ipinakita na hanay na may average na halaga ng hanay; ang isang maliit na halaga, nang naaayon, ay nagpapakita na ang mga halaga sa hanay ay nakapangkat sa paligid ng gitnang halaga.
Halimbawa, mayroon kaming tatlong hanay ng numero: (0, 0, 14, 14), (0, 6, 8, 14) at (6, 6, 8, 8). Ang lahat ng tatlong hanay ay may mga mean na halaga na katumbas ng 7, at mga karaniwang paglihis, ayon sa pagkakabanggit, katumbas ng 7, 5 at 1. Ang huling hanay ay may maliit na karaniwang paglihis, dahil ang mga halaga sa hanay ay pinagsama-sama sa average na halaga; ang unang hanay ay may pinakamalaking karaniwang halaga ng paglihis - ang mga halaga sa loob ng hanay ay lubos na nag-iiba mula sa average na halaga.
Sa pangkalahatang kahulugan, ang karaniwang paglihis ay maaaring ituring na isang sukatan ng kawalan ng katiyakan. Halimbawa, sa physics, ginagamit ang standard deviation upang matukoy ang error ng isang serye ng sunud-sunod na mga sukat ng ilang dami. Napakahalaga ng halagang ito para sa pagtukoy ng katumpakan ng hindi pangkaraniwang bagay na pinag-aaralan kung ihahambing sa halaga na hinulaang ng teorya: kung ang average na halaga ng mga sukat ay naiiba nang malaki sa mga halaga na hinulaan ng teorya (malaking standard deviation), pagkatapos ay ang mga nakuha na halaga o ang paraan ng pagkuha ng mga ito ay dapat na muling suriin.
Praktikal na paggamit
Sa pagsasagawa, pinapayagan ka ng standard deviation na matukoy kung magkano ang mga halaga sa isang set ay maaaring mag-iba mula sa average na halaga.
Klima
Ipagpalagay na mayroong dalawang lungsod na may parehong average na maximum na pang-araw-araw na temperatura, ngunit ang isa ay matatagpuan sa baybayin at ang isa ay nasa loob ng bansa. Ito ay kilala na ang mga lungsod na matatagpuan sa baybayin ay may maraming iba't ibang pinakamataas na temperatura sa araw na mas mababa kaysa sa mga lungsod na matatagpuan sa loob ng bansa. Samakatuwid, ang karaniwang paglihis ng pinakamataas na pang-araw-araw na temperatura para sa isang baybaying lungsod ay magiging mas mababa kaysa sa pangalawang lungsod, sa kabila ng katotohanan na ang average na halaga ng halagang ito ay pareho, na sa pagsasanay ay nangangahulugan na ang posibilidad na ang pinakamataas na temperatura ng hangin sa anumang partikular na araw ng taon ay magiging mas mataas na naiiba mula sa average na halaga, mas mataas para sa isang lungsod na matatagpuan sa loob ng bansa.
Palakasan
Ipagpalagay natin na mayroong ilang mga koponan ng football na sinusuri ayon sa ilang hanay ng mga parameter, halimbawa, ang bilang ng mga layunin na nakapuntos at natanggap, mga pagkakataon sa pag-iskor, atbp. Malamang na ang pinakamahusay na koponan sa pangkat na ito ay magkakaroon ng pinakamahusay na mga halaga Sa pamamagitan ng higit pa mga parameter. Kung mas maliit ang standard deviation ng team para sa bawat isa sa mga ipinakitang parameter, mas mahuhulaan ang resulta ng team ay balanse. Sa kabilang banda, ang pangkat na may malaking halaga ang karaniwang paglihis ay mahirap hulaan ang resulta, na kung saan ay ipinaliwanag ng kawalan ng timbang, halimbawa, malakas na depensa, ngunit may mahinang pag-atake.
Ang paggamit ng karaniwang paglihis ng mga parameter ng koponan ay ginagawang posible, sa isang antas o iba pa, upang mahulaan ang resulta ng isang laban sa pagitan ng dalawang koponan, pagtatasa ng mga lakas at mahinang panig mga utos, at samakatuwid ang mga piniling paraan ng pakikibaka.
Teknikal na pagsusuri
Tingnan din
Panitikan
| Ang artikulong ito ay iminungkahi para sa pagtanggal.
Ang paliwanag ng mga dahilan at ang kaukulang talakayan ay makikita sa pahina Wikipedia: Matatanggal/Disyembre 17, 2012. |
* Borovikov, V. STATISTICA. Ang sining ng pagsusuri ng data sa isang computer: Para sa mga propesyonal / V. Borovikov. - St. Petersburg. : Peter, 2003. - 688 p. - ISBN 5-272-00078-1.
| Mga tagapagpahiwatig ng istatistika | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Naglalarawan mga istatistika |
|
||||||||||
| Istatistika output at pagsusuri mga hypotheses |
| ||||||||||
Tinukoy bilang isang pangkalahatang katangian ng laki ng pagkakaiba-iba ng isang katangian sa pinagsama-samang. Ito ay katumbas ng square root ng average na square deviation ng mga indibidwal na halaga ng attribute mula sa arithmetic mean, i.e. Ang ugat ng at maaaring matagpuan tulad nito:
1. Para sa pangunahing hilera:
2. Para sa serye ng variation:

Dinadala ito ng pagbabago ng standard deviation formula sa isang form na mas maginhawa para sa mga praktikal na kalkulasyon:
Karaniwang lihis tinutukoy kung gaano karami sa average na partikular na mga opsyon ang lumihis mula sa kanilang average na halaga, at isa rin itong ganap na sukatan ng pagkakaiba-iba ng isang katangian at ipinahayag sa parehong mga yunit ng mga opsyon, at samakatuwid ay mahusay na binibigyang-kahulugan.
Mga halimbawa ng paghahanap ng standard deviation: ,
Para sa mga alternatibong katangian, ang average na formula parisukat na paglihis parang ganyan:
![]()
kung saan ang p ay ang proporsyon ng mga yunit sa populasyon na may isang tiyak na katangian;
q ay ang proporsyon ng mga yunit na walang ganitong katangian.
Ang konsepto ng average na linear deviation
Katamtaman linear deviation ay tinukoy bilang ang arithmetic mean ng mga ganap na halaga ng mga paglihis ng mga indibidwal na opsyon mula sa .
1. Para sa pangunahing hilera:

2. Para sa serye ng variation:

kung saan ang kabuuan n ay kabuuan ng mga frequency ng variation series.
Isang halimbawa ng paghahanap ng average na linear deviation:
Ang bentahe ng mean absolute deviation bilang sukatan ng dispersion sa hanay ng variation ay kitang-kita, dahil ang panukalang ito ay nakabatay sa pagsasaalang-alang sa lahat ng posibleng deviations. Ngunit ang tagapagpahiwatig na ito ay may mga makabuluhang disbentaha. Ang di-makatwirang pagtanggi sa mga algebraic na palatandaan ng mga paglihis ay maaaring humantong sa katotohanan na ang mga katangian ng matematika ng tagapagpahiwatig na ito ay malayo sa elementarya. Ginagawa nitong napakahirap gamitin ang mean absolute deviation kapag nilulutas ang mga problemang kinasasangkutan ng mga probabilistikong kalkulasyon.
Samakatuwid, ang average na linear deviation bilang isang sukatan ng pagkakaiba-iba ng isang katangian ay bihirang ginagamit sa istatistikal na kasanayan, lalo na kapag ang pagbubuod ng mga tagapagpahiwatig nang hindi isinasaalang-alang ang mga palatandaan ay may kahulugan sa ekonomiya. Sa tulong nito, halimbawa, nasuri ang turnover banyagang kalakalan, komposisyon ng mga manggagawa, ritmo ng produksyon, atbp.
Mean square
Inilapat ang ibig sabihin ng parisukat, halimbawa, upang kalkulahin ang average na laki ng mga gilid ng n square section, ang average na diameters ng mga putot, pipe, atbp. Ito ay nahahati sa dalawang uri.
Simple mean square. Kung, kapag pinapalitan ang mga indibidwal na halaga ng isang katangian ng isang average na halaga, kinakailangan na panatilihing hindi nagbabago ang kabuuan ng mga parisukat ng orihinal na mga halaga, kung gayon ang average ay magiging isang parisukat na average na halaga.
Ito ang square root ng quotient ng paghahati ng kabuuan ng mga parisukat ng mga indibidwal na halaga ng katangian sa kanilang numero:
Ang weighted mean square ay kinakalkula gamit ang formula:

kung saan ang f ay ang tanda ng timbang.
Average na kubiko
Nalalapat ang average na kubiko, halimbawa, kapag tinutukoy ang average na haba ng isang gilid at mga cube. Ito ay nahahati sa dalawang uri.
Average na cubic simple:


Kapag kinakalkula ang mga average na halaga at pagpapakalat sa serye ng pamamahagi ng agwat, ang mga tunay na halaga ng katangian ay pinapalitan ng mga sentral na halaga ng mga agwat, na naiiba sa arithmetic mean ng mga halagang kasama sa pagitan. Ito ay humahantong sa isang sistematikong error kapag kinakalkula ang pagkakaiba. V.F. Tinukoy iyon ni Sheppard error sa pagkalkula ng variance, na dulot ng paggamit ng pinagsama-samang data, ay 1/12 ng parisukat ng halaga ng pagitan, parehong sa direksyon ng pagtaas at sa direksyon ng pagpapababa ng magnitude ng dispersion.
Susog ng Sheppard dapat gamitin kung ang distribusyon ay malapit sa normal, nauugnay sa isang katangian na may tuluy-tuloy na katangian ng variation, at nakabatay sa malaking halaga ng paunang data (n > 500). Gayunpaman, batay sa katotohanan na sa ilang mga kaso ang parehong mga pagkakamali, na kumikilos sa iba't ibang direksyon, ay nagbabayad sa bawat isa, kung minsan ay posible na tumanggi na ipakilala ang mga pagwawasto.
Kung mas maliit ang pagkakaiba at karaniwang paglihis, mas homogenous ang populasyon at magiging mas tipikal ang average.
Sa pagsasagawa ng mga istatistika, madalas na kailangang ihambing ang mga pagkakaiba-iba ng iba't ibang katangian. Halimbawa, malaking interes na ihambing ang mga pagkakaiba-iba sa edad ng mga manggagawa at kanilang mga kwalipikasyon, haba ng serbisyo at laki. sahod, gastos at tubo, haba ng serbisyo at produktibidad ng paggawa, atbp. Para sa gayong mga paghahambing, ang mga tagapagpahiwatig ng ganap na pagkakaiba-iba ng mga katangian ay hindi angkop: imposibleng ihambing ang pagkakaiba-iba ng karanasan sa trabaho, na ipinahayag sa mga taon, na may pagkakaiba-iba ng sahod, na ipinahayag sa rubles.
Upang maisagawa ang mga naturang paghahambing, pati na rin ang mga paghahambing ng pagkakaiba-iba ng parehong katangian sa ilang mga populasyon na may iba't ibang mga average ng arithmetic, ito ay ginagamit kamag-anak na tagapagpahiwatig variation - koepisyent ng variation.
Mga katamtamang istruktura
Upang makilala ang sentral na tendensya sa mga distribusyon ng istatistika, madalas na makatwiran na gamitin, kasama ang arithmetic mean, ang isang tiyak na halaga ng katangian X, na, dahil sa ilang mga tampok ng lokasyon nito sa serye ng pamamahagi, ay maaaring makilala ang antas nito.
Ito ay lalong mahalaga kapag sa isang serye ng pamamahagi ang mga matinding halaga ng isang katangian ay may hindi malinaw na mga hangganan. Sa pagsasaalang-alang na ito, ang isang tumpak na pagpapasiya ng arithmetic mean ay kadalasang imposible o napakahirap. Sa ganitong mga kaso average na antas maaaring matukoy sa pamamagitan ng pagkuha, halimbawa, ng isang halaga ng tampok na matatagpuan sa gitna ng isang serye ng dalas o na madalas na nangyayari sa kasalukuyang serye.
Ang ganitong mga halaga ay nakasalalay lamang sa likas na katangian ng mga frequency, ibig sabihin, sa istraktura ng pamamahagi. Ang mga ito ay tipikal sa lokasyon sa isang serye ng mga frequency, samakatuwid ang mga naturang halaga ay itinuturing na mga katangian ng sentro ng pamamahagi at samakatuwid ay natanggap ang kahulugan ng mga istrukturang average. Sanay na silang mag-aral panloob na istraktura at ang istraktura ng serye ng pamamahagi ng mga halaga ng katangian. Kabilang sa mga naturang tagapagpahiwatig ang:
$X$. Upang magsimula, alalahanin natin ang sumusunod na kahulugan:
Kahulugan 1
Populasyon-- isang hanay ng mga random na napiling mga bagay ng isang naibigay na uri, kung saan ang mga obserbasyon ay isinasagawa upang makakuha ng mga tiyak na halaga ng isang random na variable, na isinasagawa sa ilalim ng pare-parehong mga kondisyon kapag nag-aaral ng isang random na variable ng isang naibigay na uri.
Kahulugan 2
Pangkalahatang pagkakaiba-- ang arithmetic mean ng squared deviations ng mga value ng variant ng populasyon mula sa kanilang mean value.
Hayaang ang mga halaga ng opsyon na $x_1,\ x_2,\dots ,x_k$ ay may, ayon sa pagkakabanggit, ng mga frequency na $n_1,\ n_2,\dots ,n_k$. Pagkatapos ay kinakalkula ang pangkalahatang pagkakaiba-iba gamit ang formula:
Isaalang-alang natin ang isang espesyal na kaso. Hayaang mag-iba ang lahat ng opsyon na $x_1,\ x_2,\dots ,x_k$. Sa kasong ito $n_1,\ n_2,\dots ,n_k=1$. Nalaman namin na sa kasong ito ang pangkalahatang pagkakaiba ay kinakalkula gamit ang formula:
Ang konseptong ito ay nauugnay din sa konsepto ng pangkalahatang pamantayang paglihis.
Kahulugan 3
Pangkalahatang standard deviation
\[(\sigma )_g=\sqrt(D_g)\]
Sample na pagkakaiba-iba
Bigyan tayo ng sample na populasyon na may kinalaman sa random variable na $X$. Upang magsimula, alalahanin natin ang sumusunod na kahulugan:
Kahulugan 4
Sampol na populasyon-- bahagi ng mga piling bagay mula sa pangkalahatang populasyon.
Kahulugan 5
Sample na pagkakaiba-iba-- karaniwan mga halaga ng aritmetika pagpipilian sa sampling.
Hayaang ang mga halaga ng opsyon na $x_1,\ x_2,\dots ,x_k$ ay may, ayon sa pagkakabanggit, ng mga frequency na $n_1,\ n_2,\dots ,n_k$. Pagkatapos ay kinakalkula ang sample variance gamit ang formula:
Isaalang-alang natin ang isang espesyal na kaso. Hayaang mag-iba ang lahat ng opsyon na $x_1,\ x_2,\dots ,x_k$. Sa kasong ito $n_1,\ n_2,\dots ,n_k=1$. Nalaman namin na sa kasong ito ang sample na pagkakaiba ay kinakalkula ng formula:
May kaugnayan din sa konseptong ito ang konsepto ng sample standard deviation.
Kahulugan 6
Sample na standard deviation -- Kuwadrado na ugat mula sa pangkalahatang pagkakaiba-iba:
\[(\sigma )_в=\sqrt(D_в)\]
Nawastong pagkakaiba
Upang mahanap ang naitama na variance $S^2$ kinakailangan na i-multiply ang sample na variance sa fraction na $\frac(n)(n-1)$, iyon ay
Ang konseptong ito ay nauugnay din sa konsepto ng itinamang standard deviation, na matatagpuan sa pamamagitan ng formula:
Sa kaso kapag ang mga halaga ng mga variant ay hindi discrete, ngunit kumakatawan sa mga agwat, pagkatapos ay sa mga formula para sa pagkalkula ng pangkalahatan o sample na mga pagkakaiba, ang halaga ng $x_i$ ay itinuturing na ang halaga ng gitna ng pagitan sa kung saan kabilang ang $x_i.$.
Isang halimbawa ng problema upang mahanap ang pagkakaiba at karaniwang paglihis
Halimbawa 1
Ang sample na populasyon ay tinutukoy ng sumusunod na talahanayan ng pamamahagi:
Larawan 1.
Hanapin natin para dito ang sample variance, sample standard deviation, corrected variance at corrected standard deviation.
Upang malutas ang problemang ito, gumawa muna kami ng talahanayan ng pagkalkula:
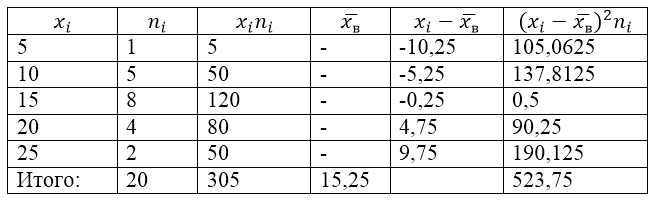
Figure 2.
Ang halaga na $\overline(x_в)$ (sample average) sa talahanayan ay matatagpuan sa pamamagitan ng formula:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15.25\]
Hanapin natin ang sample na pagkakaiba-iba gamit ang formula:
Halimbawang karaniwang paglihis:
\[(\sigma )_в=\sqrt(D_в)\approx 5.12\]
Nawastong pagkakaiba:
\[(S^2=\frac(n)(n-1)D)_в=\frac(20)(19)\cdot 26.1875\approx 27.57\]
Nawastong standard deviation.
Ayon sa sample na survey, ang mga depositor ay pinagsama ayon sa laki ng kanilang deposito sa Sberbank ng lungsod:
tukuyin:
1) saklaw ng pagkakaiba-iba;
2) average na laki ng deposito;
3) average na linear deviation;
4) pagpapakalat;
5) karaniwang paglihis;
6) koepisyent ng pagkakaiba-iba ng mga kontribusyon.
Solusyon:
Ang serye ng pamamahagi na ito ay naglalaman ng mga bukas na agwat. Sa naturang serye, ang halaga ng pagitan ng unang pangkat ay karaniwang ipinapalagay na katumbas ng halaga ng pagitan ng susunod, at ang halaga ng pagitan ng huling pangkat ay katumbas ng halaga ng pagitan ng nauna.
Ang halaga ng pagitan ng pangalawang pangkat ay katumbas ng 200, samakatuwid, ang halaga ng unang pangkat ay katumbas din ng 200. Ang halaga ng pagitan ng penultimate group ay katumbas ng 200, na nangangahulugan na ang huling pagitan ay magkakaroon din may halagang 200.
1) Tukuyin natin ang hanay ng variation bilang pagkakaiba sa pagitan ng pinakamalaki at pinakamababang halaga tanda:
Ang saklaw ng pagkakaiba-iba sa laki ng deposito ay 1000 rubles.
2) Ang average na laki ng kontribusyon ay tutukuyin gamit ang weighted arithmetic average formula.
Alamin muna natin ang discrete value ng attribute sa bawat interval. Upang gawin ito, gamit ang simpleng arithmetic mean formula, makikita natin ang mga midpoint ng mga pagitan.
Ang average na halaga ng unang agwat ay magiging:

ang pangalawa - 500, atbp.
Ilagay natin ang mga resulta ng pagkalkula sa talahanayan:
| Halaga ng deposito, kuskusin. | Bilang ng mga depositor, f | Gitna ng pagitan, x | xf |
|---|---|---|---|
| 200-400 | 32 | 300 | 9600 |
| 400-600 | 56 | 500 | 28000 |
| 600-800 | 120 | 700 | 84000 |
| 800-1000 | 104 | 900 | 93600 |
| 1000-1200 | 88 | 1100 | 96800 |
| Kabuuan | 400 | - | 312000 |
Ang average na deposito sa Sberbank ng lungsod ay magiging 780 rubles:
3) Ang average na linear deviation ay ang arithmetic mean ng absolute deviations ng mga indibidwal na halaga ng isang katangian mula sa pangkalahatang average:

Ang pamamaraan para sa pagkalkula ng average na linear deviation sa interval distribution series ay ang mga sumusunod:
1. Ang weighted arithmetic mean ay kinakalkula, tulad ng ipinapakita sa talata 2).
2. Ang mga ganap na paglihis mula sa average ay tinutukoy:
3. Ang mga resultang deviations ay pinarami ng mga frequency:
4. Hanapin ang kabuuan ng mga weighted deviations nang hindi isinasaalang-alang ang sign:
5. Ang kabuuan ng mga weighted deviations ay hinati sa kabuuan ng mga frequency:
Maginhawang gamitin ang talahanayan ng data ng pagkalkula:
| Halaga ng deposito, kuskusin. | Bilang ng mga depositor, f | Gitna ng pagitan, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 480 | 15360 |
| 400-600 | 56 | 500 | -280 | 280 | 15680 |
| 600-800 | 120 | 700 | -80 | 80 | 9600 |
| 800-1000 | 104 | 900 | 120 | 120 | 12480 |
| 1000-1200 | 88 | 1100 | 320 | 320 | 28160 |
| Kabuuan | 400 | - | - | - | 81280 |

Ang average na linear deviation ng laki ng deposito ng mga kliyente ng Sberbank ay 203.2 rubles.
4) Ang dispersion ay ang arithmetic mean ng mga squared deviations ng bawat attribute value mula sa arithmetic mean.
Ang pagkalkula ng pagkakaiba-iba sa serye ng pamamahagi ng pagitan ay isinasagawa gamit ang formula:

Ang pamamaraan para sa pagkalkula ng pagkakaiba-iba sa kasong ito ay ang mga sumusunod:
1. Tukuyin ang weighted arithmetic mean, tulad ng ipinapakita sa talata 2).
2. Maghanap ng mga paglihis mula sa average:
3. Square ang deviation ng bawat opsyon mula sa average:
4. I-multiply ang mga parisukat ng mga deviation sa pamamagitan ng mga timbang (mga frequency):
![]()
5. Isama ang mga resultang produkto:
![]()
6. Ang resultang halaga ay hinati sa kabuuan ng mga timbang (mga frequency):

Ilagay natin ang mga kalkulasyon sa isang talahanayan:
| Halaga ng deposito, kuskusin. | Bilang ng mga depositor, f | Gitna ng pagitan, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 230400 | 7372800 |
| 400-600 | 56 | 500 | -280 | 78400 | 4390400 |
| 600-800 | 120 | 700 | -80 | 6400 | 768000 |
| 800-1000 | 104 | 900 | 120 | 14400 | 1497600 |
| 1000-1200 | 88 | 1100 | 320 | 102400 | 9011200 |
| Kabuuan | 400 | - | - | - | 23040000 |
Ang matatalinong mathematician at statistician ay nakabuo ng isang mas maaasahang tagapagpahiwatig, bagaman para sa isang bahagyang naiibang layunin - average na linear deviation. Ang tagapagpahiwatig na ito ay nagpapakilala sa sukat ng pagpapakalat ng mga halaga ng isang set ng data sa paligid ng kanilang average na halaga.
Upang maipakita ang sukat ng scatter ng data, kailangan mo munang magpasya kung ano ang kakalkulahin sa scatter na ito - kadalasan ito ang average na halaga. Susunod, kailangan mong kalkulahin kung gaano kalayo ang mga halaga ng nasuri na set ng data mula sa average. Malinaw na ang bawat halaga ay tumutugma sa isang tiyak na halaga ng paglihis, ngunit kami ay interesado sa pangkalahatang pagtatasa, na sumasaklaw sa buong populasyon. Samakatuwid, ang average na paglihis ay kinakalkula gamit ang karaniwang arithmetic mean formula. Ngunit! Ngunit upang makalkula ang average ng mga paglihis, dapat muna silang idagdag. At kung magdaragdag tayo ng mga positibo at negatibong numero, kakanselahin nila ang isa't isa at ang kanilang kabuuan ay magiging zero. Upang maiwasan ito, ang lahat ng mga paglihis ay kinuha modulo, iyon ay, lahat ng mga negatibong numero ay nagiging positibo. Ngayon ang average na paglihis ay magpapakita ng isang pangkalahatang sukatan ng pagkalat ng mga halaga. Bilang resulta, ang average na linear deviation ay kakalkulahin gamit ang formula:
a- average na linear deviation,
x– ang nasuri na tagapagpahiwatig, na may gitling sa itaas – ang average na halaga ng tagapagpahiwatig,
n- bilang ng mga halaga sa nasuri na set ng data,
Sana ay walang matakot ang summation operator.
Ang average na linear deviation na kinakalkula gamit ang tinukoy na formula ay sumasalamin sa average na absolute deviation mula sa average na halaga para sa isang partikular na populasyon.

Sa larawan, ang pulang linya ay ang average na halaga. Ang mga paglihis ng bawat obserbasyon mula sa mean ay ipinahiwatig ng maliliit na arrow. Sila ay kinuha modulo at summed up. Pagkatapos ang lahat ay nahahati sa bilang ng mga halaga.
Upang makumpleto ang larawan, kailangan nating magbigay ng isang halimbawa. Sabihin nating mayroong isang kumpanya na gumagawa ng mga pinagputulan para sa mga pala. Ang bawat pagputol ay dapat na 1.5 metro ang haba, ngunit, higit sa lahat, dapat silang lahat ay pareho o hindi bababa sa plus o minus 5 cm Gayunpaman, ang mga walang ingat na manggagawa ay magpuputol ng 1.2 m o 1.8 m ang mga residente. Nagpasya ang direktor ng kumpanya na magsagawa ng statistical analysis ng haba ng mga pinagputulan. Pumili ako ng 10 piraso at sinukat ang kanilang haba, natagpuan ang average at kinakalkula ang average na linear deviation. Ang average ay naging lamang kung ano ang kinakailangan - 1.5 m Ngunit ang average na linear na paglihis ay 0.16 m Kaya lumalabas na ang bawat pagputol ay mas mahaba o mas maikli kaysa sa kinakailangan sa average ng 16 cm manggagawa. Sa katunayan, hindi ko nakita ang anumang tunay na paggamit ng tagapagpahiwatig na ito, kaya ako mismo ang gumawa ng isang halimbawa. Gayunpaman, mayroong gayong tagapagpahiwatig sa mga istatistika.
Pagpapakalat
Tulad ng average na linear deviation, ang pagkakaiba ay sumasalamin din sa lawak ng pagkalat ng data sa paligid ng mean na halaga.
Ang formula para sa pagkalkula ng pagkakaiba ay ganito ang hitsura:
 (para sa serye ng variation (weighted variance))
(para sa serye ng variation (weighted variance))
 (para sa hindi nakagrupong data (simpleng pagkakaiba))
(para sa hindi nakagrupong data (simpleng pagkakaiba))
Kung saan: σ 2 – pagpapakalat, Xi– sinusuri namin ang sq indicator (ang halaga ng katangian), – ang average na halaga ng indicator, f i – ang bilang ng mga halaga sa nasuri na set ng data.
Ang dispersion ay ang average na parisukat ng mga deviations.
Una, ang average na halaga ay kinakalkula, pagkatapos ay ang pagkakaiba sa pagitan ng bawat orihinal at average na halaga ay kinuha, parisukat, pinarami ng dalas ng katumbas na halaga ng katangian, idinagdag at pagkatapos ay hinati sa bilang ng mga halaga sa populasyon.
Gayunpaman, sa dalisay nitong anyo, tulad ng arithmetic mean, o index, hindi ginagamit ang dispersion. Ito ay isang pantulong at intermediate na tagapagpahiwatig na ginagamit para sa iba pang mga uri ng istatistikal na pagsusuri.
Isang pinasimpleng paraan upang makalkula ang pagkakaiba
![]()
Karaniwang lihis
Upang magamit ang pagkakaiba para sa pagsusuri ng data, ang square root ng pagkakaiba ay kinuha. Ito pala ang tinatawag na karaniwang lihis.

Sa pamamagitan ng paraan, ang karaniwang paglihis ay tinatawag ding sigma - mula sa letrang Griyego na nagsasaad nito.
Ang karaniwang paglihis, malinaw naman, ay nagpapakilala rin sa sukatan ng pagpapakalat ng data, ngunit ngayon (hindi katulad ng pagkakaiba-iba) ito ay maihahambing sa orihinal na data. Bilang isang tuntunin, ang root mean square measure sa mga istatistika ay nagbibigay ng mas tumpak na mga resulta kaysa sa mga linear. Samakatuwid, ang standard deviation ay isang mas tumpak na sukatan ng dispersion ng data kaysa sa linear mean deviation.